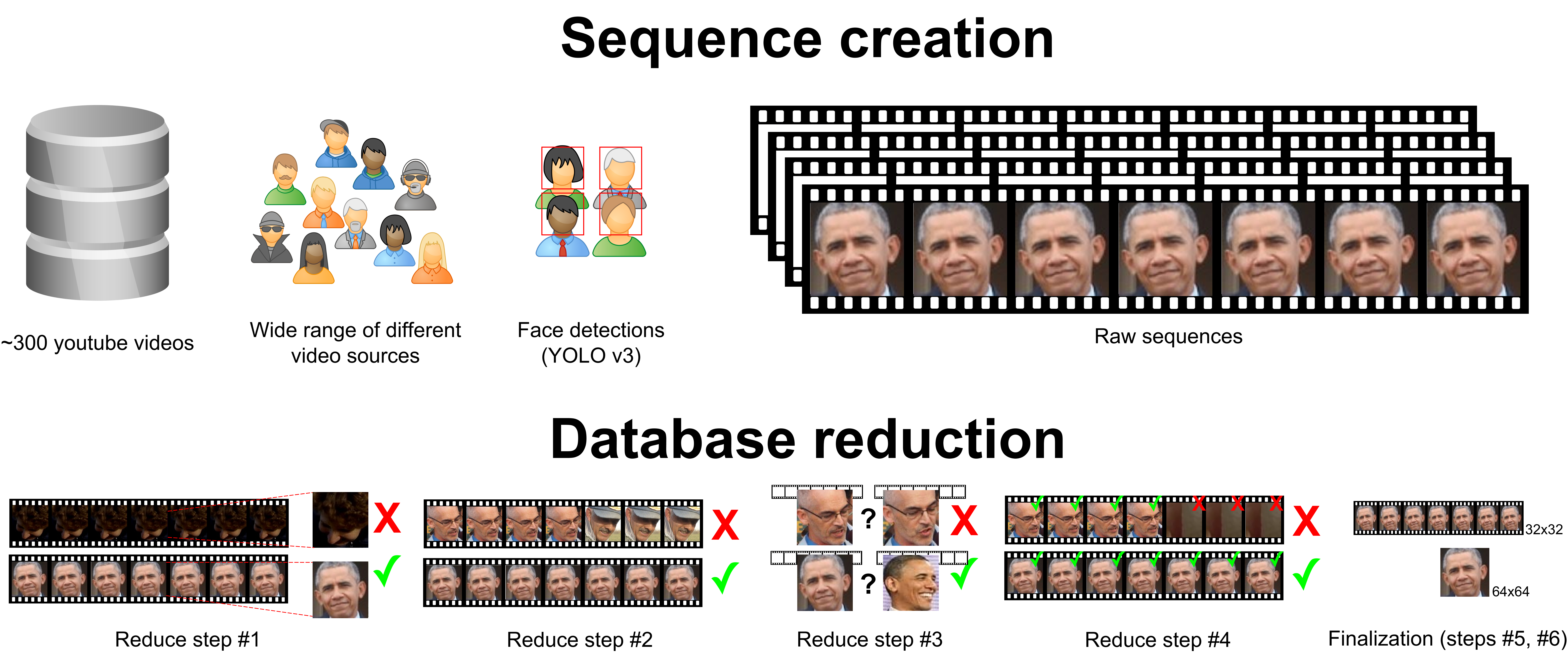
The dataset was created from +- 300 youtube videos and there are approx. 6,000 - 7,000 different persons (computed by face-recognition framework [2] based on Facenet [3]). Sequences from one video source were filtering using SSIM metric with threshold 0.7 (only labels were compared) to assure different scale, lighting, angles… even there is a same person (more details in „how was it created“ part). The dataset contains almost 17500 samples – (sequences with label), it is divided into few sets with approx. ratio 70/15/15%:


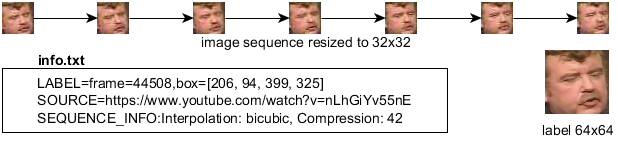
One of the state-of-the-art face detector – YOLO v3 [4] and its implementation [5] was used for face detection. Images that had at least 64x64 resolution were also filtered in this step. Label and its bounding box and frame number was recorded. Detections were taken from randomly chosen frames in the video. Raw sequences were created using OpenCV [6] framework. It found corresponding label frame, cropped image based on bounding box and finally took 3 frames before and 3 frames after and cropped them using same bounding box. This was intentional step to make database more realist as there are many cases when face detector do not correctly crop the face (not accurate detection, crop scaling factor,…). Amount of raw sequences is 36,123. There are few filtration steps that need to be done before final database is ready:
Licence and Conditions for youtube.com can be seen here: conditions and terms. We selected the most important points:
TRAINING DATA are publicly available and contain TRAIN and TEST set. The database is provided as .ZIP file.
You need to fill up the request form and agree with terms of use to download MLFDB database.
The training data contains info files, image sequences and labels.
TESTING DATA are also available as .ZIP file and there are two sets - Test set for overall evaluation and objective metrics computation and Questionnaire data for optional subjective human evaluation.
Labels are not available! If you want to evaluate your model, follow the instructions in Results section. We provide automatic evaluation.
You need to write your email address that was used for downloading training data. Terms of use has to be again accepted.
| # | Team | Members | Affiliation | Method | Score | Attempts |
|---|---|---|---|---|---|---|
| 1 | BUT_AI | M. Rajnoha, A. Mezina, R. Burget | Brno University of Technology, Czech Rebublic | U-Net+GEU3 | 1.297 | 1 |
@article{rajnoha2020mlfdb,
title={Multi-Frame Labeled Faces Database: Towards Face Super-Resolution from Realistic Video Sequences},
author={Rajnoha, Martin and Mezina, Anzhelika and Burget, Radim},
journal={Applied Sciences},
volume={10},
number={20},
pages={7213},
year={2020},
publisher={Multidisciplinary Digital Publishing Institute}
}
[1] RAJNOHA, Martin; MEZINA, Anzhelika; BURGET, Radim. Multi-Frame Labeled Faces Database: Towards Face Super-Resolution from Realistic Video Sequences. Appl. Sci. 2020, 10, 7213.
[2] https://github.com/ageitgey/face_recognition version 1.3.0 with CNN detector.
[3] SCHROFF, Florian; KALENICHENKO, Dmitry; PHILBIN, James. Facenet: A unified embedding for face recognition and clustering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. p. 815-823.
[4] REDMON, Joseph; FARHADI, Ali. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[5] https://github.com/sthanhng/yoloface
[6] https://pypi.org/project/opencv-python/
[7] HUANG, Gary B., et al. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. (http://vis-www.cs.umass.edu/lfw/)


